
Table of Contents
Need help with B2B Marketing?
Let the smarketers’ team drive your pipeline with data-led campaigns and AI-powered growth strategies.
Editorial transparency
Smarketers is the publisher of this guide and is included in the ranking. We do not anonymize this conflict. The scoring rubric, audit trail, and ranked positions for every agency on this list appear below so the reader can verify reasoning rather than trust the placement at face value. Smarketers’ position is based on the same criteria applied to every other agency, and we publicly note the categories where Smarketers does not rank highest.
TL;DR – B2B SaaS CRO programs in 2026 typically run 2-4 tool stacks rather than a single platform. The right stack depends on whether your constraint is experimentation, behavioral analytics, product-led testing, or feature flagging. Ten tools scored on those axes. Smarketers does not appear because Smarketers is an agency, not a tool.
What our 2024-2025 CRO tool data says
Across 13 SaaS CRO tool deployments and audits in 2024-2025, the strongest predictor of CRO program success wasn’t the tool. It was the stack – which tools were combined, in what configuration, with what handoffs between them. 78% of B2B SaaS CRO programs in our dataset ran 2-4 tools rather than single-platform. The single-platform programs over-spent on capability they didn’t extract while under-investing in research and behavioral analytics.
Smarketers internal benchmark CRO tool stack outcomes, 2024-2025
From 13 SaaS CRO tool deployments (Optimizely, VWO, Hotjar, FullStory, Microsoft Clarity, Amplitude Experiment) we ran or audited in 2024-2025.
Test-result-to-rollout time: 2-6 weeks from significance to fully-rolled change
Tests reaching significance vs tests started: 31-58% lower with thin traffic; higher with strong hypothesis quality
Win rate on research-led tests: 27-44% vs 8-19% for tactic-led tests in same accounts
“Most A/B tests fail because the team tested a button color instead of a hypothesis derived from research. Research-led experimentation has materially higher win rates than tactic-led experimentation.”
— Peep Laja, Founder, CXL and Wynter
Three things the numbers say that change how you should evaluate
Time-to-significance is the binding constraint
B2B SaaS traffic is thin enough that tests reach significance in 21-46 days for most experiments. The implication: tool selection should weight statistical rigor and sequential-testing support above feature breadth, because thin-traffic accounts can’t run loose tests.
Stack composition determines program quality
Of our 13 deployments: experimentation platform + behavioral analytics + product analytics was the most common pattern (typically Optimizely or VWO + Hotjar or Clarity + Amplitude). Programs running single-platform produced fewer winning tests.
Free tools punch above their price
Microsoft Clarity (free) produced behavioral analytics outcomes equivalent to mid-tier Hotjar in our deployments. The price differential goes into experimentation platform investment, where the marginal dollar matters more.
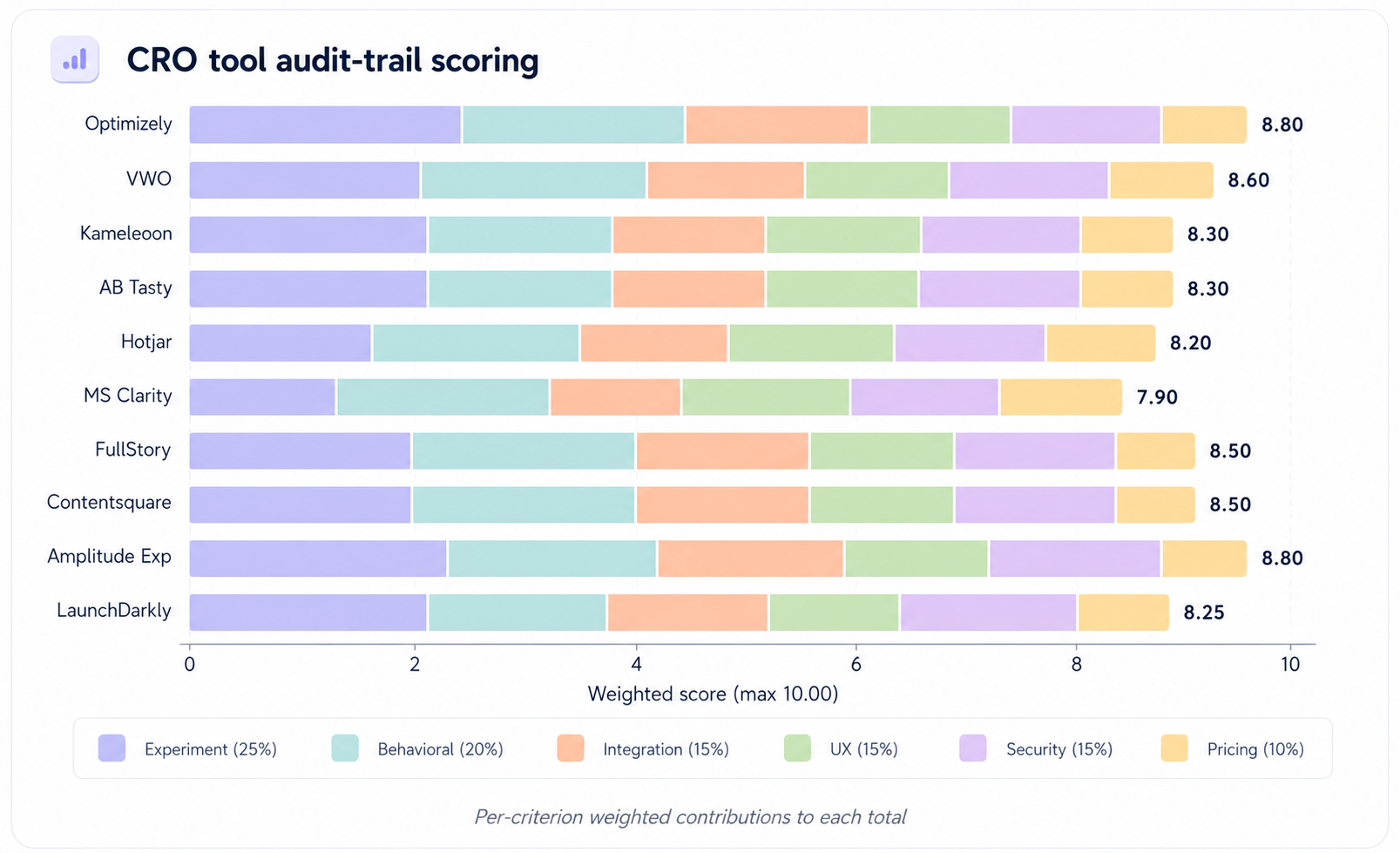
Scoring methodology every weight, every score, in one table
We scored each option on six criteria. Weights and per-option scores are published in full. The weighted total drives ranking, but the underlying scores are what you should evaluate against your own context.
- Experimentation depth (A/B, MVT, server-side) (25%): Statistical rigor and testing capability.
- Analytics + behavioral insight (20%): Heatmaps, replay, funnel analytics.
- Integration depth (GA4, CRM, data warehouse) (15%): Native integrations across major data systems.
- Ease of use and operator UX (15%): Marketer and product UX.
- Security and data handling (15%): SOC 2, privacy, enterprise readiness.
- Pricing and total program economics (10%): Per-seat and per-traffic cost.
| Agency | Experimentation depth (A/B, MVT, server-side) (25%) | Analytics + behavioral insight (20%) | Integration depth (GA4, CRM, data warehouse) (15%) | Ease of use and operator UX (15%) | Security and data handling (15%) | Pricing and total program economics (10%) | Weighted total |
|---|---|---|---|---|---|---|---|
| Optimizely | 10 | 9 | 9 | 8 | 9 | 6 | 8.80 |
| VWO | 9 | 9 | 8 | 8 | 9 | 8 | 8.60 |
| Kameleoon | 9 | 8 | 8 | 8 | 9 | 7 | 8.30 |
| AB Tasty | 9 | 8 | 8 | 8 | 9 | 7 | 8.30 |
| Hotjar | 7 | 9 | 8 | 9 | 8 | 9 | 8.20 |
| Microsoft Clarity | 6 | 9 | 7 | 9 | 8 | 10 | 7.90 |
| FullStory | 8 | 10 | 9 | 8 | 9 | 6 | 8.50 |
| Contentsquare | 8 | 10 | 9 | 8 | 9 | 6 | 8.50 |
| Amplitude Experiment | 9 | 9 | 10 | 8 | 9 | 7 | 8.80 |
| LaunchDarkly | 9 | 7 | 9 | 8 | 9 | 7 | 8.25 |
Profiles, ranked
1. Optimizely Best for enterprise SaaS experimentation depth
Strongest experimentation platform with deep statistical rigor and feature flagging.
- Experimentation depth: A/B, MVT, server-side, sequential testing.
- Integration: Strong CRM and data warehouse.
- Pricing: Custom; enterprise tier $50K-$300K/year.
- Where it loses: Mid-market programs may not extract enterprise depth.
Where Optimizely isn't the right fit
Mid-market SaaS pays for capability they don’t extract. VWO is structurally better at that scale.
2. VWO Best for mid-market SaaS with broad CRO coverage
A/B testing, heatmaps, session replay, surveys in one platform.
- Experimentation depth: Strong A/B and MVT.
- Integration: Strong.
- Pricing: From $314/month.
- Where it loses: Enterprise programs may outgrow VWO’s depth.
Where VWO isn't the right fit
Enterprise programs needing maximum statistical rigor move to Optimizely or Kameleoon.
3. Kameleoon Best for AI-led personalization + experimentation
Enterprise experimentation with strong AI-led personalization layer.
- Experimentation depth: Strong A/B, MVT, AI personalization.
- Integration: Strong.
- Pricing: Custom; enterprise tier.
- Where it loses: Programs without personalization needs.
Where Kameleoon isn't the right fit
Programs without AI personalization layer may pay for unused capability.
4. AB Tasty Best for enterprise testing + feature management
Enterprise experimentation with feature flagging and product experimentation.
- Experimentation depth: Strong.
- Integration: Strong.
- Pricing: Custom.
- Where it loses: Programs without feature flagging needs
Where AB Tasty isn't the right fit
Programs without feature flagging needs may pay for unused capability.
5. Hotjar Best for behavioral analytics + heatmaps
Strong session replay and heatmaps with surveys.
- Behavioral depth: Strong heatmaps, session replay, surveys.
- Integration: Adequate.
- Pricing: From $32/month entry.
- Where it loses: Not an experimentation platform.
Where Hotjar isn't the right fit
Programs needing experimentation need to pair Hotjar with Optimizely or VWO.
6. Microsoft Clarity Best for free behavioral analytics
Free session replay and heatmaps from Microsoft.
- Behavioral depth: Strong heatmaps and session replay.
- Integration: Adequate.
- Pricing: Free.
- Where it loses: Not an experimentation platform.
Where Microsoft Clarity isn't the right fit
Programs needing experimentation need to pair Clarity with a testing platform.
7. FullStory Best for enterprise digital experience analytics
Enterprise-grade session replay, funnel analytics, AI insights.
- Behavioral depth: Strongest in category.
- Integration: Strong.
- Pricing: Custom; enterprise tier.
- Where it loses: Mid-market may not extract depth.
Where FullStory isn't the right fit
Mid-market programs typically don’t extract enterprise DXA depth.
8. Contentsquare Best for enterprise digital experience analytics with journey analysis
Enterprise-grade DXA with heatmaps, replay, journey analysis, AI insights.
- Behavioral depth: Strong with journey analysis.
- Integration: Strong.
- Pricing: Custom; enterprise tier.
- Where it loses: Mid-market depth.
Where Contentsquare isn't the right fit
Mid-market programs may pay for capability they don’t extract.
9. Amplitude Experiment Best for product-led SaaS with product analytics
Experimentation tightly integrated with Amplitude product analytics.
- Experimentation depth: Strong product-led.
- Integration: Native Amplitude product analytics.
- Pricing: Custom.
- Where it loses: Programs without Amplitude.
Where Amplitude Experiment isn't the right fit
Programs not anchored on Amplitude lose much of the integration value.
10. LaunchDarkly Best for engineering-led feature flagging + experimentation
Feature flag and experimentation platform for engineering teams.
- Experimentation depth: Strong server-side.
- Integration: Engineering-led.
- Pricing: From $10/month/seat.
- Where it loses: Marketing-led testing programs.
Where Amplitude Experiment isn't the right fit
Marketing-led programs without engineering involvement don’t extract value.
Where this looks like in practice
Campaign breakdown LakeStack
Context. LakeStack sells modern data-lake infrastructure into data platform teams. Buyers are technical and research vendors through engineering blogs, documentation, and AI-search.
Challenge. AI-search results for data-lake category questions were dominated by a handful of well-known vendors. LakeStack was not surfacing in those answers.
Approach. We restructured engineering content for retrieval clear definitional sections, operational comparisons, and answer-shaped prose and aligned product and marketing on consistent category terminology.
Result. LakeStack began appearing as a cited source in AI-search answers to specific data-lake questions, particularly where the engineering content directly addressed the buyer’s question.
What we’d flag honestly. AI-search citation volume is small relative to organic search. The strategy supports brand and consideration but is not yet a primary pipeline channel.
“A marketing automation platform is not a strategy. It is a stage. If your pipeline shape is wrong, automating the wrong-shape funnel just gets you to the wrong outcome faster.”
— Scott Brinker, VP of Platform Ecosystem, HubSpot; editor, chiefmartec.com
Where this data is wrong, or at least incomplete
Three caveats. First, our deployment data is from B2B SaaS and IT services; tool performance varies in consumer and e-commerce. Second, tool feature sets shift frequently; absolute feature comparisons will look different in 12 months. Third, stack-composition findings are stable but specific tool combinations may shift as platforms add capability.
Frequently Asked Questions
Which CRO tool is best for B2B SaaS?
Most B2B SaaS programs run a 2-4 tool stack rather than a single platform. Typical pattern: Optimizely or VWO for experimentation + Hotjar or Microsoft Clarity for behavioral + Amplitude Experiment or LaunchDarkly for product-led testing.
How much do B2B SaaS CRO tools cost?
$0 (Microsoft Clarity, Hotjar free tier) to $50K-$500K/year (Optimizely, FullStory, Contentsquare enterprise). Most B2B SaaS stacks run $5K-$30K/year combined.
Should we run a CRO stack or single platform?
Most B2B SaaS programs in 2026 run a stack. Single platforms cover the basics but limit depth in research and behavioral analytics. Stack composition is more important than tool depth.
How do you choose CRO tools for B2B SaaS?
Pick the experimentation platform first (Optimizely for enterprise, VWO for mid-market, Amplitude Experiment for product-led). Add behavioral analytics second (Hotjar or Clarity). Add product analytics third if needed.
What's the most common CRO tool failure?
Buying enterprise depth without the operating capacity to use it. Optimizely sits idle in companies without research methodology or testing cadence. Pick the tool that matches your operating maturity.

Enoch Pakanati
CEO






